Определение пиковых значений измеряемого сигнала
мы используем карту сбора данных для снятия показаний с устройства, которое увеличивает свой сигнал до пика, а затем возвращается к исходному значению. Чтобы найти пиковое значение, мы в настоящее время ищем массив для самого высокого чтения и используем индекс для определения времени пикового значения, которое используется в наших расчетах.
Это хорошо работает, если самое высокое значение-это пик, который мы ищем, но если устройство работает неправильно, мы можем увидеть второй пик, который может быть выше, чем начальный пик. Мы принимаем 10 показаний в секунду от 16 устройств в течение 90-секундного периода.
мои первоначальные мысли состоят в том, чтобы циклически проверять показания, чтобы увидеть, если предыдущая и следующая точки меньше, чем текущая, чтобы найти пик и построить массив пиков. Возможно, мы должны смотреть на среднее число точек по обе стороны от текущего положения, чтобы учесть шум в системе. Это лучший способ или есть лучше техники?
мы используем LabVIEW и я проверил лава форумов и есть ряд интересных примеров. Это часть нашего тестового программного обеспечения, и мы стараемся избегать использования слишком большого количества нестандартных библиотек VI, поэтому я надеялся на обратную связь по процессу/алгоритмам, а не по конкретному коду.
9 ответов:
вы можете попробовать усреднить сигнал, т. е. для каждой точки, усреднить значение с окружающими 3 или более точек. Если шумовые всплески огромны, то даже это может не помочь.
Я понимаю, что это был язык агностик, но предполагая, что вы используете LabView, есть много предварительно упакованных VIs обработки сигналов, которые поставляются с LabView, которые можно использовать для сглаживания и шумоподавления. Элемент ни форумов являются отличным местом, чтобы получить более специализированную помощь по этому виду конечно.
есть много и много классических методов обнаружения пиков, любой из которых может работать. Вы должны будете увидеть, что, в частности, ограничивает качество ваших данных. Вот основные описания:
между любыми двумя точками в ваших данных,
(x(0), y(0))и(x(n), y(n))доy(i + 1) - y(i)на0 <= i < nи назвать этоT("путешествие") и setR("рост") кy(n) - y(0) + kдля достаточно малыхk.T/R > 1указывает на пик. Это работает нормально, если большое путешествие из-за шума маловероятно или если шум распределяется симметрично вокруг формы базовой кривой. Для вашего приложения примите самый ранний пик со счетом выше заданного порога или проанализируйте кривую перемещения на значения подъема для более интересных свойств.используйте согласованные фильтры для оценки сходства со стандартной формой пика (по существу, используйте нормализованное точечное произведение против некоторой формы, чтобы получить Косинус-метрику сходства)
деконволюции против стандартная форма пика и проверка на высокие значения (хотя я часто нахожу, что 2 менее чувствительны к шуму для простого выхода измерительной аппаратуры).
сгладьте данные и проверьте триплеты равномерно расположенных точек, где, если
x0 < x1 < x2, y1 > 0.5 * (y0 + y2), или проверить евклидовы расстояния, как это:D((x0, y0), (x1, y1)) + D((x1, y1), (x2, y2)) > D((x0, y0),(x2, y2)), которая опирается на неравенство треугольника. Использование простых соотношений снова предоставит вам механизм подсчета очков.установите очень простую 2-гауссовскую модель смеси ваши данные (например, числовые рецепты имеют хороший готовый кусок кода). Возьмите более ранний пик. Это будет правильно работать с перекрывающимися пиками.
найдите лучшее совпадение в данных с простой кривой Гаусса, Коши, Пуассона или чего-то еще. Оцените эту кривую в широком диапазоне и вычтите ее из копии данных, отметив ее пиковое местоположение. Повторять. Возьмите самый ранний пик, параметры модели которого (стандартное отклонение, вероятно, но некоторые приложения могут заботиться о эксцессе или других особенностях) отвечают некоторым критериям. Следите за артефактами, оставленными позади, когда пики вычитаются из данных. Лучший матч может быть определен по типу подсчета очков матча, предложенного в № 2 выше.
Я сделал то, что ты делаешь раньше: нахождение вершины в данных о последовательности ДНК, нахождение вершин в производные финансовые инструменты оцениваются на основе измеренных кривых и нахождение пиков на гистограммах.
Я призываю вас внимательно к правильной базовой линии. Фильтрация Винера или другая фильтрация или простой анализ гистограммы часто является простым способом определения базовой линии в присутствии шума.
наконец, если ваши данные обычно зашумлены, и вы получаете данные с карты как несвязанный односторонний выход (или даже ссылаетесь, просто не дифференцированный), и если вы усредняете множество наблюдений в каждой точке данных, попробуйте отсортировать эти наблюдения и выбросить первый и последний квартиль и усреднить то, что осталось. Есть множество таких тактик исключения выбросов, которые могут быть действительно полезны.
эта проблема была изучена достаточно подробно.
есть набор очень современных реализаций в
TSpectrum*классы ROOT (инструмент анализа физики ядерных/частиц). Код работает в одно-и трехмерных данных.корневой исходный код доступен, так что вы можете захватить эту реализацию, если хотите.
С TSpectrum документация класс:
алгоритмы, используемые в этом классе были опубликованы в следующих источниках:
[1] M. Morhac et al.: Фон методы исключения для многомерное совпадение гамма-излучения спектр. Ядерные инструменты и Методы исследования в физике 401 (1997) 113- 132.
[2] M. Morhac et al.: Эффективное одно - и двумерное золото деконволюция и ее применение к разложение гамма-спектров. Ядерные инструменты и методы в Исследование Физики 401 (1997) 385-408.
[3] M. Morhac et al. Идентификация пиков многомерное совпадение гамма-излучения спектр. Ядерные инструменты и Методы исследования в физике 443(2000), 108-125.
документы связаны с документацией класса для тех из вас, у кого нет подписки NIM online.
короткая версия того, что делается, заключается в том, что гистограмма сглажена для устранения шума, а затем обнаруживаются локальные максимумы грубая сила в сплющенной гистограмме.
Я хотел бы внести свой вклад в этот поток алгоритм, который я развил себя:
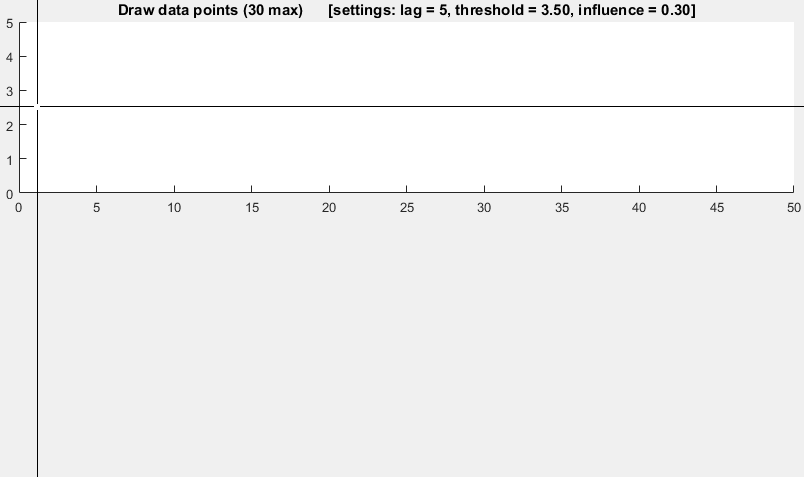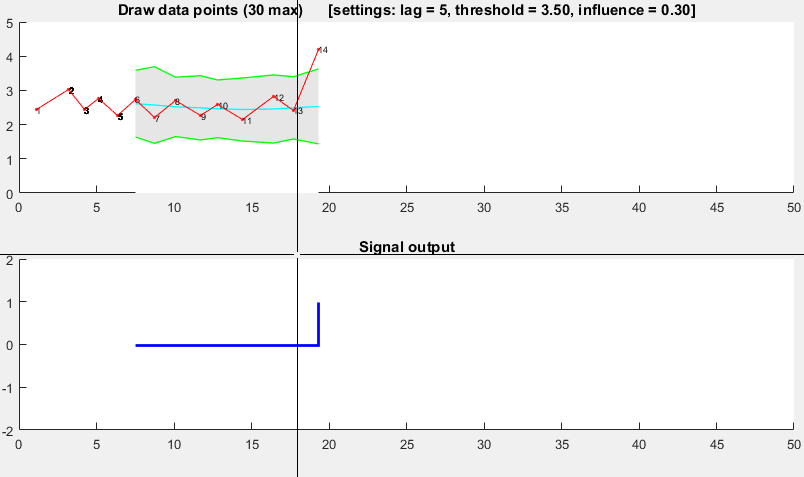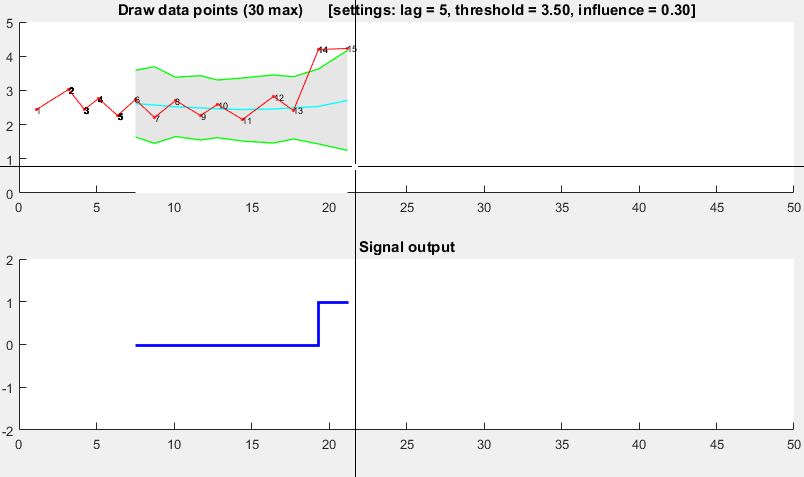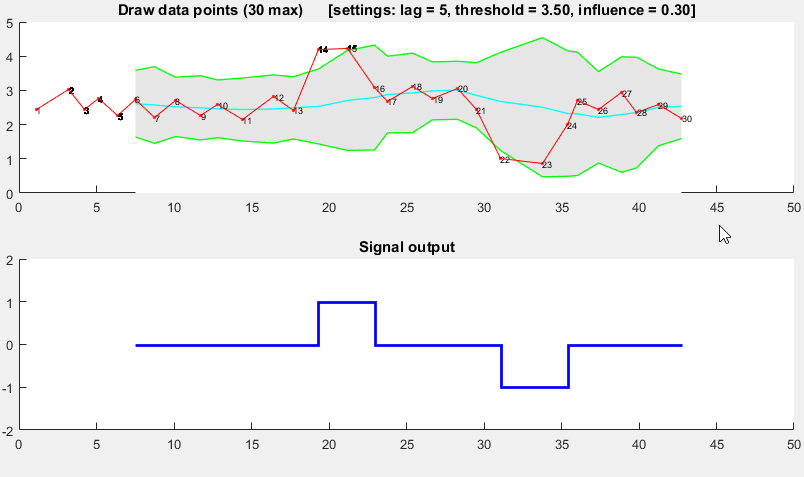
он основан на принципе дисперсия: если новая точка данных представляет собой заданное x число стандартных отклонений от некоторого скользящего среднего, алгоритм сигнализирует (также называемый z-score). Алгоритм очень надежен, потому что он строит отдельные moving среднее и отступление, такие что сигналы не повреждают порог. Поэтому будущие сигналы идентифицируются приблизительно с одинаковой точностью, независимо от количества предыдущих сигналов. Алгоритм принимает 3 входа:
lag = the lag of the moving window,threshold = the z-score at which the algorithm signalsиinfluence = the influence (between 0 and 1) of new signals on the mean and standard deviation. Например,lagиз 5 будет использовать последние 5 наблюдений для сглаживания данных. Аthreshold3,5 будет сигнализировать, если точка данных составляет 3,5 стандартных отклонения от скользящего среднего. И ещеinfluenceна 0,5 дает сигналы пол о влиянии, которое оказывают обычные точки данных. Аналогично,influence0 полностью игнорирует сигналы для пересчета нового порога: поэтому влияние 0 является наиболее надежным вариантом.он работает следующим образом:
псевдокод
# Let y be a vector of timeseries data of at least length lag+2 # Let mean() be a function that calculates the mean # Let std() be a function that calculates the standard deviaton # Let absolute() be the absolute value function # Settings (the ones below are examples: choose what is best for your data) set lag to 5; # lag 5 for the smoothing functions set threshold to 3.5; # 3.5 standard deviations for signal set influence to 0.5; # between 0 and 1, where 1 is normal influence, 0.5 is half # Initialise variables set signals to vector 0,...,0 of length of y; # Initialise signal results set filteredY to y(1,...,lag) # Initialise filtered series set avgFilter to null; # Initialise average filter set stdFilter to null; # Initialise std. filter set avgFilter(lag) to mean(y(1,...,lag)); # Initialise first value set stdFilter(lag) to std(y(1,...,lag)); # Initialise first value for i=lag+1,...,t do if absolute(y(i) - avgFilter(i-1)) > threshold*stdFilter(i-1) then if y(i) > avgFilter(i-1) set signals(i) to +1; # Positive signal else set signals(i) to -1; # Negative signal end # Adjust the filters set filteredY(i) to influence*y(i) + (1-influence)*filteredY(i-1); set avgFilter(i) to mean(filteredY(i-lag,i),lag); set stdFilter(i) to std(filteredY(i-lag,i),lag); else set signals(i) to 0; # No signal # Adjust the filters set filteredY(i) to y(i); set avgFilter(i) to mean(filteredY(i-lag,i),lag); set stdFilter(i) to std(filteredY(i-lag,i),lag); end end
демо
> оригинальный ответ
этот метод в основном из книги Дэвида Марра "видение"
Гауссовское размытие вашего сигнала с ожидаемой шириной ваших пиков. это избавляет от шумовых всплесков, и ваши фазовые данные не повреждены.
затем обнаружение края (журнал будет делать)
тогда ваши края были краями объектов (например, пики). посмотрите между краями для пиков, сортировать пики по размеру, и вы сделали.
Я использовал вариации на эту тему, и они работают очень хорошо.
Я думаю, что вы хотите кросс-корреляции ваш сигнал с ожидаемым, образец сигнала. Но прошло так много времени с тех пор, как я изучал обработку сигналов, и даже тогда я не обращал особого внимания.
вы могли бы применить некоторые Стандартные Отделения к вашей логике и обратите внимание на пики над x%.
Я не очень много знаю о инструментовке, поэтому это может быть совершенно непрактично, но опять же это может быть полезно в другом направлении. Если вы знаете, как показания могут отказать, и есть определенный интервал между пиками, учитывая такие сбои, почему бы не сделать градиентный спуск на каждом интервале. Если спуск приведет вас обратно в область, которую вы искали раньше, вы можете отказаться от нее. В зависимости от формы выбранной поверхности, это также может помочь вам найти пики быстрее, чем поиск.
есть ли качественная разница между желаемым пиком и нежелательным вторым пиком? Если оба пика являются "острыми" - т. е. короткими по времени-при просмотре сигнала в частотной области (путем выполнения БПФ) вы получите энергию в большинстве полос. Но если" хороший "пик надежно имеет энергию, присутствующую на частотах, не существующих в" плохом " пике, или наоборот, вы можете автоматически дифференцировать их таким образом.
Comments