NATS очень клевые, вот реально штука огонь, но у них что-то явно пошло не так и разработка воткнула. Steaming ну умеет масштабироваться, сторадж, блин, они хранят все в протобафе и не используют сжатие, по месту он жрет как вне себя, детские болезни типа он пишет журнал, но если файлики данных покараптились и он должен (сам должен, есть там все для этого!!!) восстановится, то он тупо падает, так как там что-то напутано с путями и он их просто не видит, на что Козлович просто разводит руками.
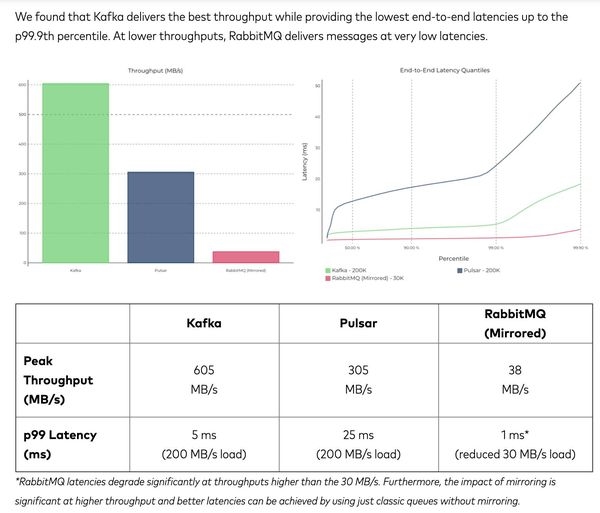
Видеть в этом тесте rabbitmq конечно забавно, это как Майк Тайсон (в лучшие годы) против бойца за сорок.Понятно что kafka быстрее и даже понятно за счет чего (батчи, формат данных на диске такой же как в сети, правильное использование pagecache, sendfile, fsync пореже и т.д.).В kafka скорее всегда были вопросы по двум вещам:1. operations2. гарантии не потерять.
А что за вопросы? Любопытно.Потому что мы в баду немного помучались, но это был больше вопрос наработки операционного опыта и экспертизы, нежели прямо каких-то фундаментальных проблем (чтобы форкать кафку).Если интересны детали, то тут (https://www.youtube.com/watch?v=m5CDfrQLzrs)
Артем, ну вот у меня лично после просмотра доклада лишь укоренилось мнение о том, что Кафка хоть и быстрая, но из коробки не делает всё, как надо, и при обновлении тоже любит всё ломать... В общем, для относительно простой задачи "перелива из пустое в порожнее" она уж больно много внимания требует, и её легко настроить неправильно и терять много данных. В этом плане мне намного больше нравится, как реализована репликация в ClickHouse, например: там при вставке (да, большими блоками нужно вставлять, это минус) просто добавляется в ZooKeeper инструкция на скачивание нового куска, и оно совершенно точно рано или поздно дойдет до другой реплики и не будет "случайно" затерто. И более свежие версии ClickHouse умеют читать более старые файлы. Но даже когда обновлен один узел кластера, а остальные ещё нет, куски в новом формате просто ждут своей очереди, пока не обновятся остальные узлы. Данные при этом тоже не теряются. Что мешало кафке сделать также по-человечески, я лично не очень понимаю.
Я очень хорошо отношусь к Kafka, но это же классика жанра - Confluent, который есть работодатель для большинства коммитеров и PMC в Apache Kafka, и который умеет ее готовить, говорит, что она самая быстрая. Чистый маркетинг <img height="16" width="16" alt="😊" referrerpolicy="origin-when-cross-origin" src="https://static.xx.fbcdn.net/images/emoji.php/v9/t7f/1/16/1f60a.png"> Но вообще это сравнение кислого с холодным. Kafka изначально делали под high-throughput ingestion streams и бигдату c "миллионами" сообщений в секунду, а Rabbit это message broker общего назначения, который поддерживает основные протоколы и используется в long-running data proсessing или микросервисах.
Alexey Romanenko ну я поэтому и написал «ожидаемо», но не согласен про кисло-холодное: message broker и event streaming достаточно «естественно» слить в один инструмент, чем меньше компонент - тем проще.
Alexey Romanenko попытки использовать rabbitmq в es были, сам видел. Но кто поопытнее,те сначала бенчмарки конечно делали. И там сразу все было понятно.
Ну не знаю, Фиш, всё-таки это совсем разные вещи. Обычные сервера очередей худо-бедно но поддерживают отслеживание состояния обработки конкретной задачи из очереди (я так понимаю, обычно используя трекинг состояния TCP-соединения), и некоторые из них даже умеют повторно засылать задачи из очереди на обработку, тогда как event streaming может тебе только отдать сразу миллион записей за раз, и если один из миллиона ты не смог обработать, то это твои проблемы, как ты с этим будешь разбираться . То есть, для этих двух систем нужны принципиально разные реализации и структуры данных, и слить их в одно даже если можно, то не думаю, что получится хорошо.
Привет! А есть чуть больше деталей benchmark? Сейчас это просто изображение, которое не раскрывает никаких деталей самого сравнения, анализ не выглядит полным, более того почему сравнивается mb/s, но не изучается комплексный вариант tp/s + mb/s.
Alexey Rybak вопрос: если тут rabbit, то сравнивался: 1) функционал именно очередей? 2) но тогда у них разные возможности по обработке и 3) а где тогда Тарантул? LSM-очередь очень хороша
Comments