Как понять локальность чувствительного хеширования?
Я заметил, что LSH кажется хорошим способом найти подобные элементы с свойствами высокого размера.
после прочтения статьи http://www.slaney.org/malcolm/yahoo/Slaney2008-LSHTutorial.pdf, я все еще путаюсь с этими формулами.
кто-нибудь знает блог или статью, которая объясняет, что простой способ?
5 ответов:
лучший учебник, который я видел для LSH, находится в книге: добыча массивных наборов данных. В Главе 3 - Находить Похожие Товары http://infolab.stanford.edu/~ullman / mmds / ch3a. pdf
также я рекомендую ниже слайд: http://www.cs.jhu.edu/%7Evandurme/papers/VanDurmeLallACL10-slides.pdf . Пример на слайде очень помогает мне понять хеширование для косинусного сходства.
Я беру два слайда из Benjamin Van Durme & Ashwin Lall, ACL2010 и попытаться объяснить интуиции семейств LSH для косинусного расстояния немного.
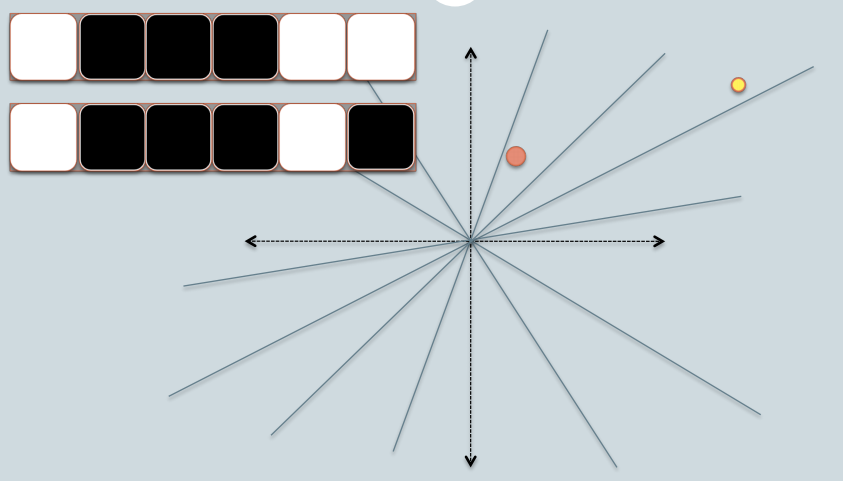
- на рисунке, есть два круга Вт/ красный и желтое цветные, представляющие две двумерные точки данных. Мы пытаемся найти их Косинус сходство С помощью LSH.
- серые линии-это несколько равномерно случайно выбранных плоскостей.
- в зависимости от того, является ли точка данных располагается выше или ниже серой линии, мы отмечаем это отношение как 0/1.
- в верхнем левом углу есть два ряда белых / черных квадратов, представляющих подпись двух точек данных соответственно. Каждый квадрат соответствует биту 0(белый) или 1 (черный).
- поэтому, как только у вас есть пул плоскостей, вы можете кодировать точки данных с их местоположением, соответствующим плоскостям. Представьте себе, что когда у нас больше плоскостей в пуле, угловая разница закодирована в подпись ближе к фактической разнице. Потому что только плоскости, которые находятся между двумя точками, дадут двум данным разное битовое значение.
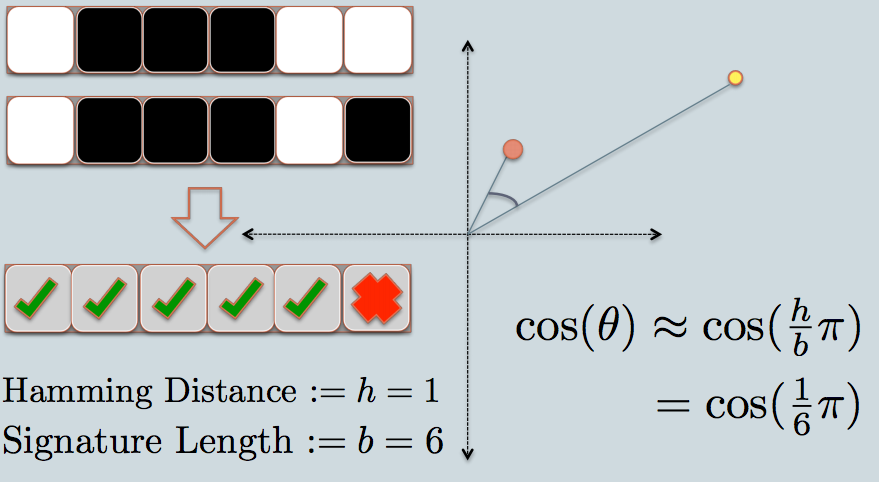
- теперь мы посмотрим на подпись двух точек данных. Как в примере, мы используем только 6 бит(квадраты) для представления данных. Это LSH-хэш для исходных данных, которые у нас есть.
- расстояние Хэмминга между двумя хэшированными значениями равно 1, потому что их сигнатуры отличаются только на 1 бит.
- учитывая длину подписи, мы можем вычислить их угловые сходство, как показано на графике.
У меня есть пример кода (всего 50 строк) в python здесь, который использует косинусное сходство. https://gist.github.com/94a3d425009be0f94751
твиты в векторном пространстве могут быть отличным примером высокомерных данных.
проверьте мой пост в блоге о применении чувствительного к локальности хэширования к твитам, чтобы найти похожие.
http://micvog.com/2013/09/08/storm-first-story-detection/
и потому, что одно изображение-это тысяча слов, проверьте изображение ниже:
http://micvog.files.wordpress.com/2013/08/lsh1.png
надеюсь, что это помогает. @mvogiatzis
вот презентация из Стэнфорда, которая объясняет это. Для меня это имело большое значение. Часть вторая больше о LSH, но часть первая охватывает его также.
изображение обзора (есть гораздо больше на слайдах):
Поиск ближнего соседа в высокомерных данных-Часть1: http://www.stanford.edu/class/cs345a/slides/04-highdim.pdf
Поиск ближнего соседа в данных высокой размерности - Часть2: http://www.stanford.edu/class/cs345a/slides/05-LSH.pdf
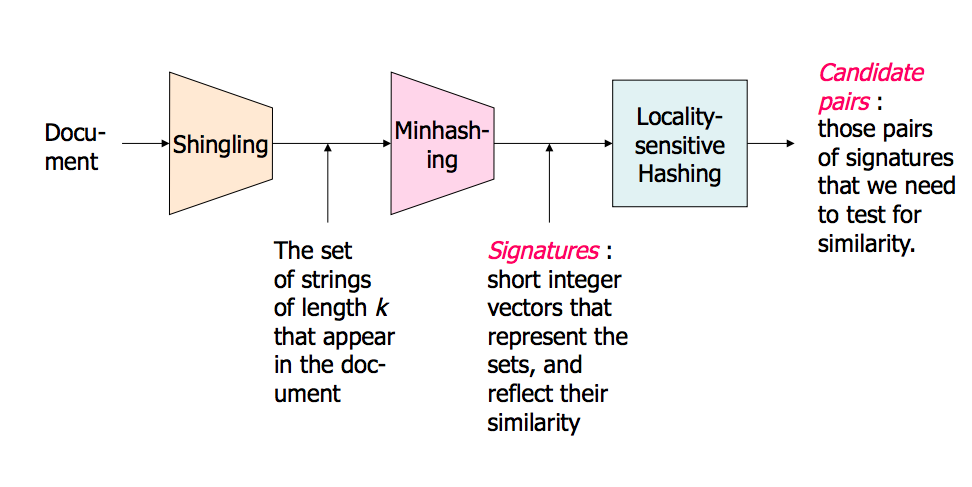
- LSH-это процедура, которая принимает в качестве входных данных набор документов/изображений / объектов и выводит своего рода хэш-таблицу.
- индексы этой таблицы содержат такие документы, что документы, находящиеся в одном индексе, считаются как и те, на разных индексах"несхожих".
- здесь как зависит от метрической системы, а также на порог подобия s, который действует как глобальный параметр ЛШ.
- это до вас, чтобы определить, что адекватный порог s - это для вашей проблемы.
важно подчеркнуть, что различные меры сходства имеют различные реализации LSH.
в своем блоге я попытался подробно объяснить LSH для случаев minHashing (мера сходства jaccard) и simHashing (мера расстояния Косинуса). Я надеюсь, что вы найдете его полезный: https://aerodatablog.wordpress.com/2017/11/29/locality-sensitive-hashing-lsh/
{kind=link}
Я визуальный человек. Вот что работает для меня, как интуиция.
скажите, что каждая из вещей, которые вы хотите найти, примерно являются физическими объектами, такими как яблоко, куб, стул.
моя интуиция для LSH заключается в том, что он похож на тени этих объектов. Например, если вы берете тень 3D-Куба, вы получаете 2D-квадрат на листе бумаги, или 3D-сфера даст вам круглую тень на листе бумаги.
В конце концов, в задаче поиска существует много более трех измерений (где каждое слово в тексте может быть одним измерением), но тени аналогия все еще очень полезна для меня.
теперь мы можем эффективно сравнивать строки битов в программном обеспечении. Битовая строка фиксированной длины более или менее похожа на линию в одном измерении.
таким образом, с помощью LSH я проецирую тени объектов в конечном итоге как точки (0 или 1) на одну линию фиксированной длины / бит строка.
2D рисунок Куба в перспективе говорит мне, что это куб. Но я не могу легко отличить 2D-квадрат от 3D-тени куба без перспективы: они оба выглядят как квадрат для меня.
Как я представляю свой объект на свет будет определять, если я получаю хороший узнаваемая тень или нет. Поэтому я думаю о "хорошем" LSH как о том, который повернет мои объекты перед светом таким образом, что их тень лучше всего распознается как представляющая мой объект.
Итак, чтобы резюмировать: я думаю о вещах для индексирования с помощью LSH как физических объектов, таких как куб, стол или стул, и я проецирую их тени в 2D и в конечном итоге вдоль линии (битовая строка). И" хорошая "функция LSH-это то, как я представляю свои объекты перед светом, чтобы получить приблизительно различимое форма в 2D flatland, а затем моя битовая строка.
наконец, когда я хочу найти, похож ли объект, который у меня есть, на некоторые объекты, которые я индексировал, я беру тени этого объекта "запроса", используя тот же способ представления моего объекта перед светом (в конечном итоге тоже с битовой строкой). И теперь я могу сравнить, насколько похожа эта битовая строка со всеми моими другими индексированными битовыми строками, которые являются прокси для поиска всех моих объектов, если я нашел хороший и узнаваемый способ представь мои объекты моему свету.
Comments